
목차
 0. 들어가며
0. 들어가며


해당 아티클을 통해 아래와 같은 정보를 얻어가실 수 있어요.
•
유저 행동 지표 (Performance Metrics)에서 사용성 문제 찾기
◦
태스크 성공, 소요 시간, 에러, 효율, 배움을 어떻게 측정하고 해석할까요?
•
자기 보고 지표 (Self-reported Metrics) 활용 가이드라인
◦
수집을 설계하고, 분석하는 가이드라인까지 표준 툴들과 함께 살펴볼게요.
1. Performance Metrics (성능 지표) 챕터
1.0. Intro
1.
기술을 사용하는 그 누구든, 목표를 달성하기 위해서는 특정 종류의 인터페이스와 상호작용하게 된다. 이런 인터페이스와 상호작용하게 되는 그 결과로, Performance Metrics가 파생된다.
2.
그 어떠한 사용자 행동도 특정한 방식을 통해 측정이 가능하다. 다만, Performance Metrics의 경우 사용자 행동에만 의존하는 것이 아닌, 사용 시나리오 및 태스크에 따라 달라진다. 목표하는 태스크가 없다면 Performance Metrics는 의미를 잃게 된다.
예로, 웹 사이트를 목적 없이 후루룩 브라우징 한다면?
•
성공적인지, 아닌지 평가할 수 있을까요?
예로, 스웨터의 가격을 찾거나 소비 리포트를 제출한다면?
•
성공을 측정할 수 있겠죠.
3.
목표하는 태스크는 사용자에게 우리가 임의로 제공하는 그런 태스크라는 의미는 아니다. 라이브 웹사이트에서, 우리가 의도했던 아니든 사용자들이 하고 싶은 어떤 행동이 태스크가 될 수도 있다. 사용성 테스트에서 직접 원하는 태스크를 만들어낼 수도 있을 것이다.
1.1. 기본기
Performance Metrics의 이점
1.
Performance Metrics는 수많은 다른 제품에서 효과성과 효율성을 평가할 수 있는 장점이 있다.
2.
특정 사용성 문제의 규모(Magnitude)를 추정할 수 있다. 이 문제가 얼마나 많은 사용자들이 경험하고 있는 문제인지, 얼마나 중요한 문제인지를 표현할 수 있다.
3.
시니어 매니저 및 주요 관계자의 경우 비용을 줄이거나 매출을 증대시킬 수 있는 잠재 요인으로 Performance Metrics을 인식하기도 한다.
Performance Metrics의 유의점
1.
모든 상황에서의 해결책은 아니며, 다른 형태의 지표에 대비하여 충분한 샘플 사이즈가 필요하다.
2.
최소 10명에게서 데이터를 수집할 수 있을 때, 의미 있는 성능 지표를 도출할 수 있으며 그 수가 더 많을 수록 좋다. 성능 지표의 경우 신뢰 구간과 주로 함께 이야기 되기 대문에 샘플 사이즈에 따라 그 신뢰 구간이 드라마틱하게 변화한다.
3.
성능 지표는 What을 효과적으로 설명해주지만, Why는 설명해주지 못한다. 성능 데이터는 어떤 부분의 인터페이스 또는 어떤 태스크가 사용자에게 문제인지를 짚어주지만, 왜 문제였으며 어떻게 고칠지에 대한 방안은 알려주지 않는다. 따라서 종종 관측형 또는 자기보고 형태의 지표들과 함께 보완하기도 한다.
Performance Metrics의 종류
1.
Task Success
2.
Time-on-task
3.
Errors
4.
Efficiency
5.
Learnablity
1.2. Task Success
1.
성공을 Binary로 측정할 수도 있고, Level으로 측정할 수도 있다.
2.
성공을 측정하기 위해서는 명백한 완료 상태가 존재해야 한다. 데이터 수집 이전에 <완료>에 대한 성공 기준을 마련하자.
a.
IBM 주식의 5-year gain or loss를 찾으세요. (명백)
b.
퇴직을 위해 저축할 방법을 리서치하세요. (명백 X)
때로는 성공 기준이 명백하지 않은 태스크 종류에 대한 UX 연구를 하기도 하지만, 태스크 성공 지표는 어느 상황에서나 명백해야 한다.
수집 방법
1.
태스크를 완료한 후 입으로 소리 내어 말하기
2.
온라인 툴으로 기록하기
3.
종이에 작성하기
성공 여부 (Binary Success)
•
상황 : 제품의 성공이 사용자로 하여금 특정 태스크 또는 일련의 태스크를 완료하는 데에 달려 있다면 적절하다.
◦
근접해지는 것은 소용이 없을 때 적절하다.
◦
e.g. 웹사이트에서 책 구매하기
•
분석 방법 : 1,0으로 기록한다. 태스크의 평균을 내고, 참가자별 평균을 낸다.
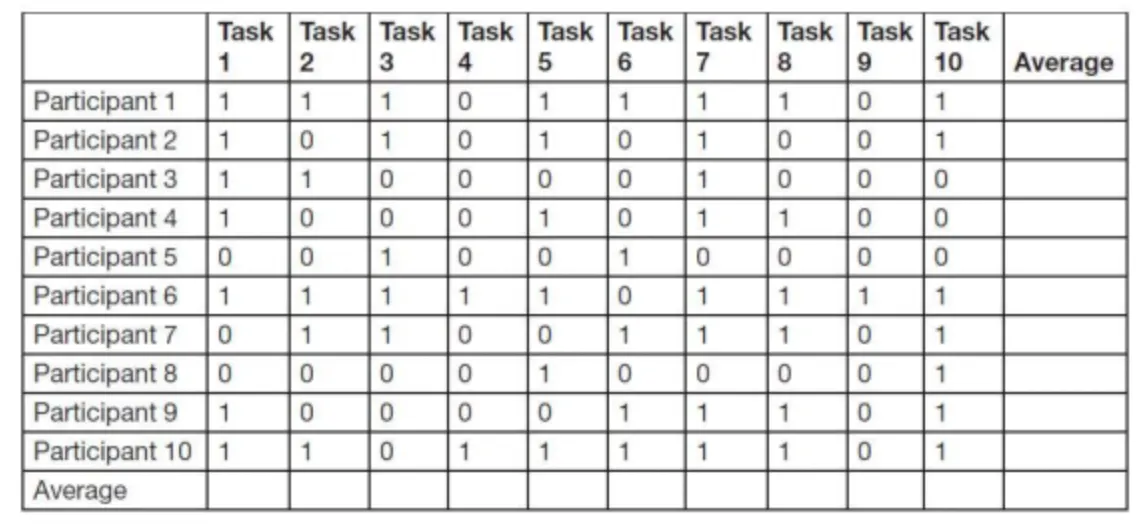
•
시각화 방법
◦
태스크별 성공 비율
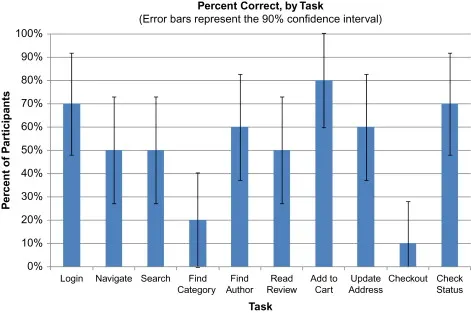
◦
유저 세그먼트에 따라, 태스크 성공 비율이 어떻게 달라지는지
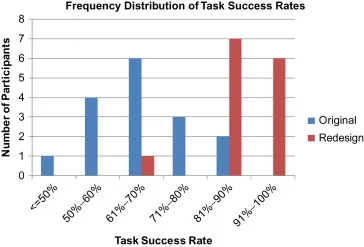
◦
성공 여부를 비율 구간에 따른 히스토그램으로 그림
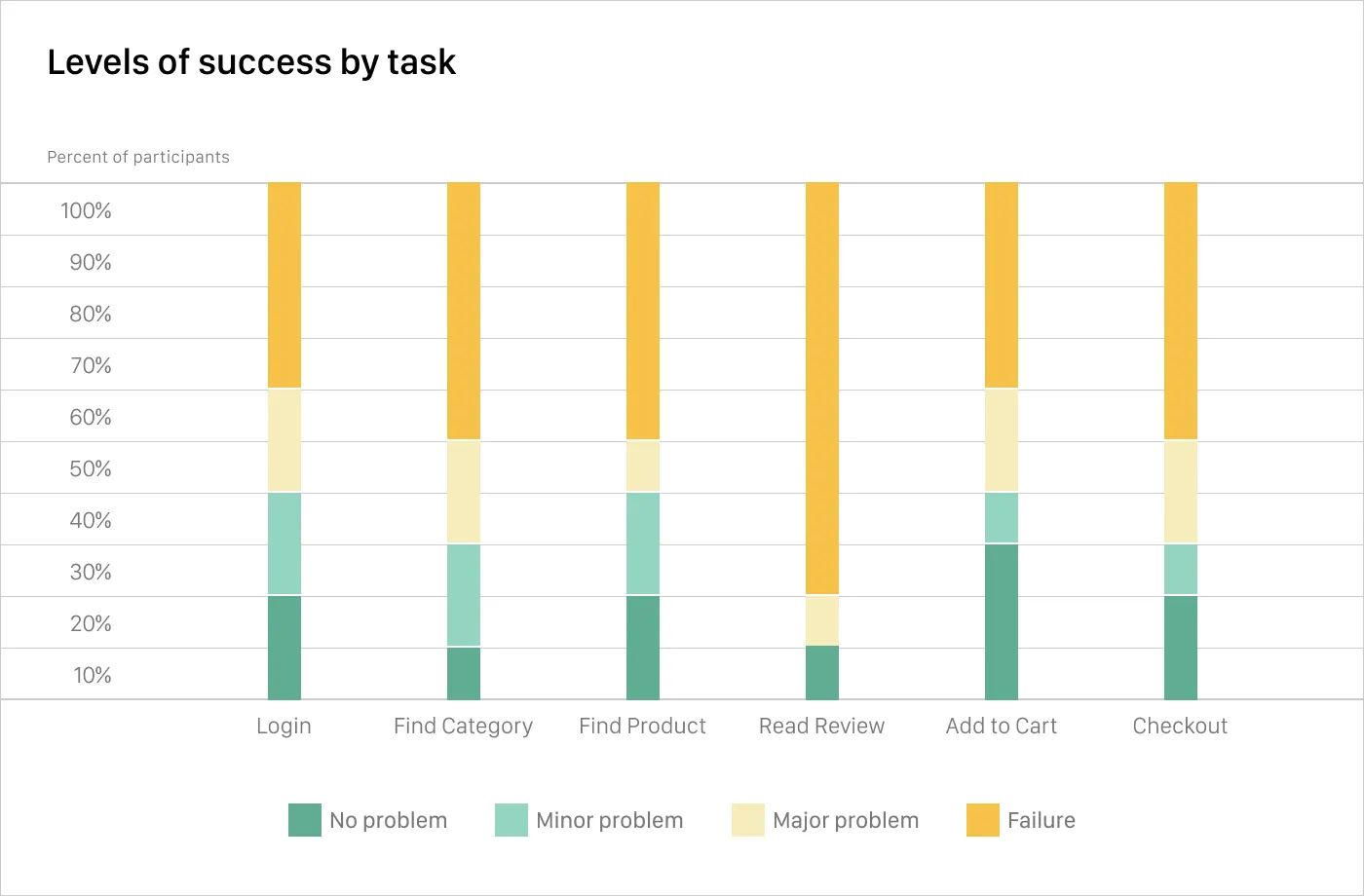
단계별 성공 (Levels of Success)
•
상황 : 태스크 성공과 관련하여 합리적인 회색 영역이 있을 때, 엄격한 성공 여부 관점으로는 실패가 되지만 굉장히 중요한 정보일 때
◦
e.g. 8 메가픽셀에 3 파운드 미만의 카메라를 찾는게 태스크면, 필터를 실수하여 5 메가픽셀에 3 파운드 미만의 카메라를 찾게 되면 “실패”인가?
▪
“어느 정도 성공”이라고 볼 수 있다는 관점.
▪
또한 어떤 태스크에 도움이 필요한지, 왜 실패했는지에 대한 정보를 얻을 수 있어 유용할 것이다.
•
분석 방법 :
◦
성공 / 부분적 성공 / 완전한 실패 3단계로 분류하는 편이다. (주로 3 ~ 6 단계)
▪
성공 (도움 O / X)
▪
부분적 성공 (도움 O / X)
▪
완전한 실패 (도움 O / X)
•
시각화 방법 :
◦
스택드 바 차트
유의점
1.
때로는 실제 성공 여부와 관계 없이 사용자가 만족하기도 한다.
2.
태스크 성공은 자기 보고 형식으로 기록도 가능하다.
e.g. 웹사이트에서 의원 후보의 포지션을 찾는 것이 태스크 성공
→ 찾았다 / 못 찾았다 / 불확실하다.
3.
성공에 대한 기준이 애매하면, 케이스들에 대해서 실험자들이 모여서 의견의 합치를 이뤄라.
1.3. Time-on-task
대부분의 상황에서, 태스크를 빨리 완성할수록 경험은 좋아진다. 물론 그렇지 않은 상황도 있는데,
•
e.g. 게임과 같은 경우는 사용자가 너무 빨리 끝내고 싶지 않을 것이다.
•
e.g. 온라인 교육의 경우 사용자가 일정 시간을 쓰며 수행해야 제대로 된 학습이 가능할 것이다.
태스크 소요 시간 vs 세션 체류시간
1.
UX 관점과 Web Analytics 관점은 상충된다.
•
UX : “대부분의 상황에서, 태스크를 빨리 완성할수록 경험은 좋아진다. “
•
Web Analytics : “사이트 또는 페이지에 길게 체류할수록, 더 많이 참여한 것이며 Sticky하다고 볼 수 있다.”
2.
본 책에서는, 세션과 페이지 뷰 체류시간은 사이트의 주인 입장에서가 아닌 사용자 입장에서 해석되어야 하는 지표라고 주장한다. 사이트에서 효율적으로 시간을 최소로 보내고 싶을 것이라는 가정이다.
3.
두 가지 관점을 상충할 수 있는 방법이 있다. 사이트의 목적에 따라 달라질 것이다고 해석하는 관점이다.
•
In-depth 또는 복잡한 태스크를 수행해야 하는 사이트 : 더 긴 세션 체류시간이 예상된다.
•
피상적인 태스크를 수행해야 하는 사이트 : 세션 체류시간 짧을 수록 좋을 것이다.
분석 방법, 아웃라이어 제거가 중요
1.
연구자가 생각했을 때, 정말 숙달된 사람이라면 태스크를 수행하는 데에 걸리는 시간을 Minimum acceptable time으로 설정한다.
2.
이 시간보다 더 적게 걸린 케이스의 경우, 제대로 시도를 안해서 유난히 짧게 걸린 아웃라이어일 수 있다. 해당 평가자가 다른 태스크에서는 성공했는지 또는 시간이 어느 정도 소요되었는지를 기반으로 아웃라이어로 판단하여 분석 대상에서 제거할 수 있다.
1.4. Efficiency
Lostness 지표
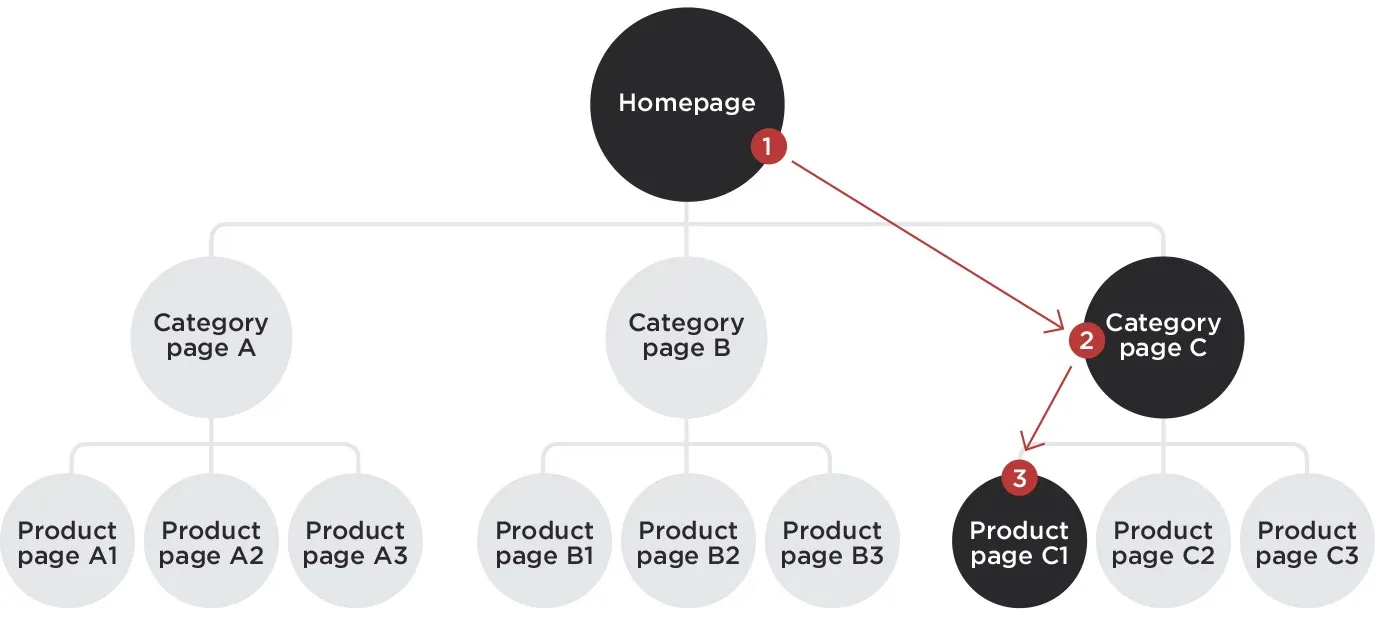
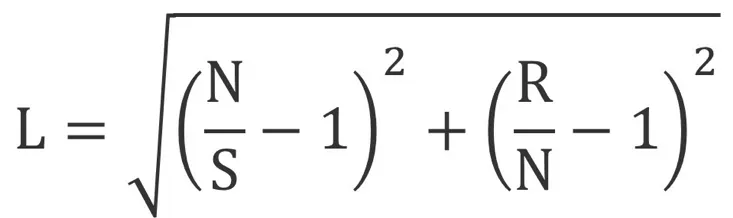
•
L is lostness.
•
N is the number of different pages visited while performing a task.
•
S is the total number of pages visited while performing the task, counting revisits to the same page.
•
R is the minimum (optimum) number of pages that must be visited to complete a task. (최적의 경로일 때 개수)
태스크 성공과 소요 시간의 조합 지표
Task Completion Rate / Task time = Efficiency
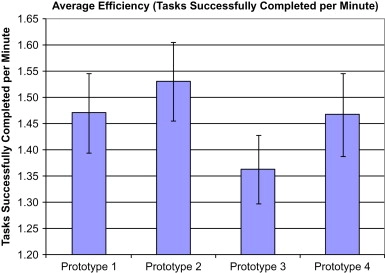
•
각 프로토타입의 효율 지표를 평균 내어 비교
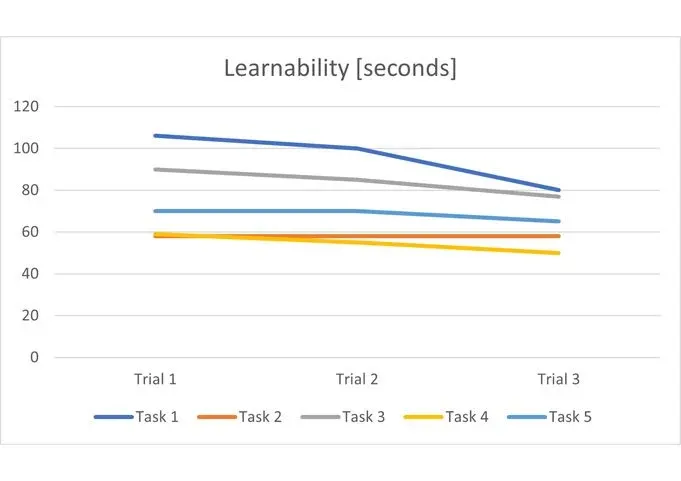
1.5. Learnability
1.
배움은 시간, 주, 월, 연에 따라 걸쳐 일어날 수 있다.
2.
만약 짧은 기간 내에 배움이 일어난다면, 사용자는 태스크를 완료하기 위해서 다양한 전략을 택해볼 것이다.
3.
Trial이 몇 차례 반복됨에 따라 어느 정도 시간이 소요되는지를 측정하며, 기울기를 비교한다.
1.6. Summary
1.
태스크 성공 지표는 사용자가 제품에서 태스크를 완수할 수 있는지에 관심이 있을 때에 활용된다. 성공은 여부와 단계로 구분될 수 있으며, 단계와 같은 경우는 완성의 정도 / 사용자의 경험 / 답변의 퀄리티에 기반한다.
2.
태스크 소요 시간 지표는 사용자가 제품에서 태스크를 얼마나 빠르게 수행하느냐에 관심이 있을 때에 활용된다. 전체 사용자 / 일부 사용자 / 특정 시간 제한 내에서 수행 가능한 사용자 세그먼트별로 확인할 수 있다.
3.
효율성은 인지적 / 물리적 소요되는 노력을 측정하는 방법이다. 태스크를 달성하기 까지 몇 번의 액션이 있었는지 또는 태스크의 성공 비율 / 태스크의 소요 시간을 나누어서 확인할 수 있다.
4.
배움은 지표가 시간에 따라 어떻게 변화하는지 보며 판단한다.
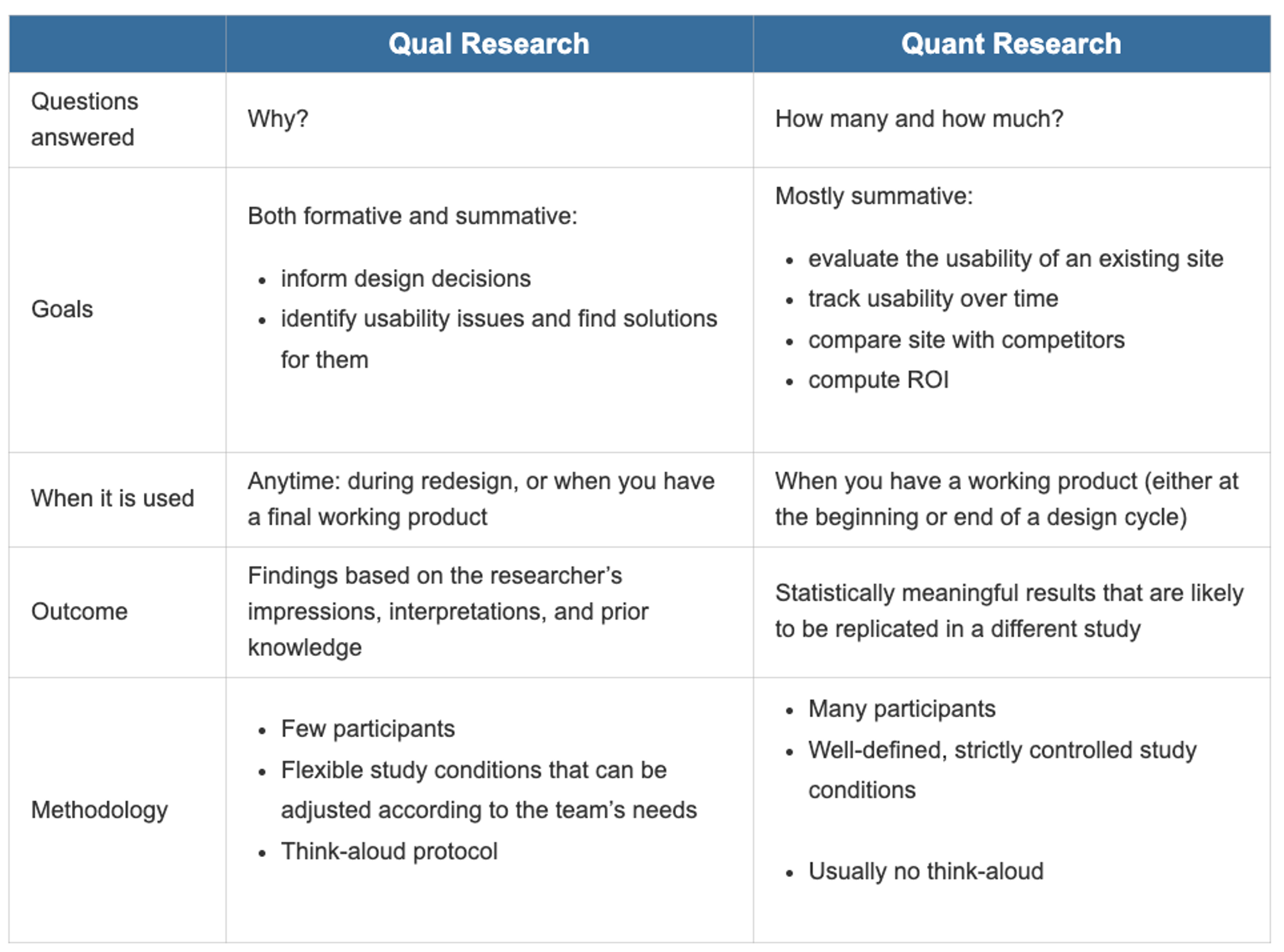
2. Self-Reported Metrics (자기 보고 지표) 챕터
2.0. Intro
1.
사용자 경험에 대해 가장 명백히 배울 수 있는 방법은 직접 경험에 대해 말해달라고 물어보는 것이다. 하지만 어떻게 물어야 좋은 데이터를 수집할 수 있을지는 명백한 답이 없다.
2.
self-reported data는 사용자가 직접 응답을 선택하는 데이터이다.
3.
최근 연구에서 가장 많이 평가되는 UX Dimension은 감정, 즐거움, 아름다움이다.
4.
self-reported data는 subjective data, preference data 2가지로도 설명된다. subjective는 objective의 반대말, preference는 performance의 반대말이다.
5.
self-reported data는 시스템에 대한 사용자의 인식과 상호작용에 대한 가장 중요한 정보를 제공한다. 사용자들의 주관적인 반응은 미래에 재방문하거나 구매하게 되는 가능성에 대한 가장 좋은 예측 변수가 된다.
2.1. 평가 척도 기본기 (Rating Scales)
2.1.1. 주요 척도 2가지
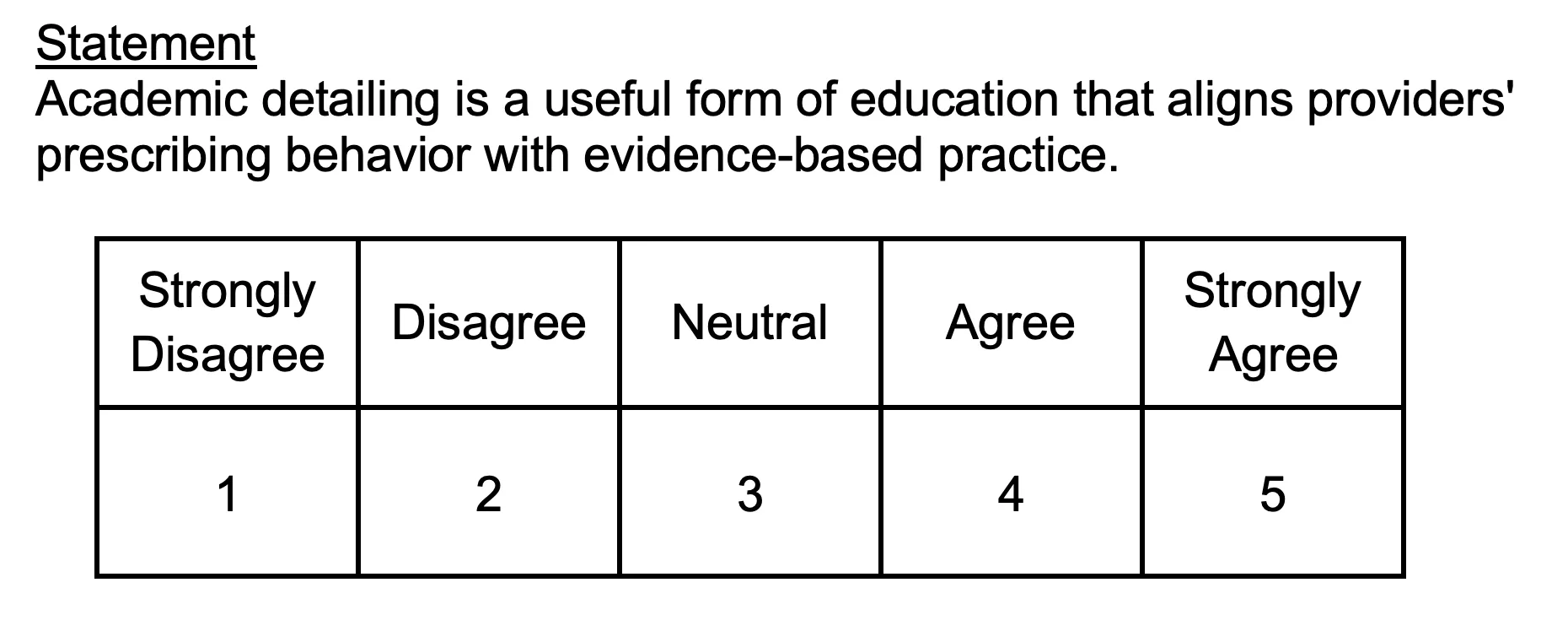
Likert Scales (리커트 척도)
•
주로 5-point scale으로 구성된다.
•
각 선택지에 라벨을 모두 붙이기보다는 양 극단 선택지 2개에만 라벨을 붙일지, 중앙을 포함하여 선택지 3개에 라벨을 붙이는 경우가 많다. 연구자의 영역이다.
•
리커트 척도의 주된 특성은 (1) 문장으로 동의의 정도를 나타낸다. (2) 중립 응답이 가능하다.
•
주로 오른쪽이 동의하는 쪽으로 구성한다.
•
Very, Extremely, Absolutely와 같은 극단적인 단어는 문장에 넣지 않는게 좋다. 이 경우, 강한 동의의 가능성이 줄어든다.
Semantic Differential Scales (의미미분법 척도)

•
선택지의 양 극단에 특성이 정반대인 형용사를 적는다.
•
주로 5-point scale, 7-point scale로 구성된다.
•
단어 선택이 중요하다.
◦
예시) Friendly vs Unfriendly / Not Friendly / Hostile 이 가지는 의미가 모두 다르다.
둘 중 뭐가 나을까?

•
연구 결과 둘 다 동등하게 잘 작동하는 것을 발견했다.
•
묵인 편향 (acquiescence bias)으로 보통 “동의”라는 단어가 포함된 문장이 보이면 더 동의하려고 하는 경향이 있다.
◦
하지만, 실제 실험 결과 리커트 척도보다 의미미분법 척도에서 더 높은 평균값이 나왔기 때문에 가설은 기각되었다.
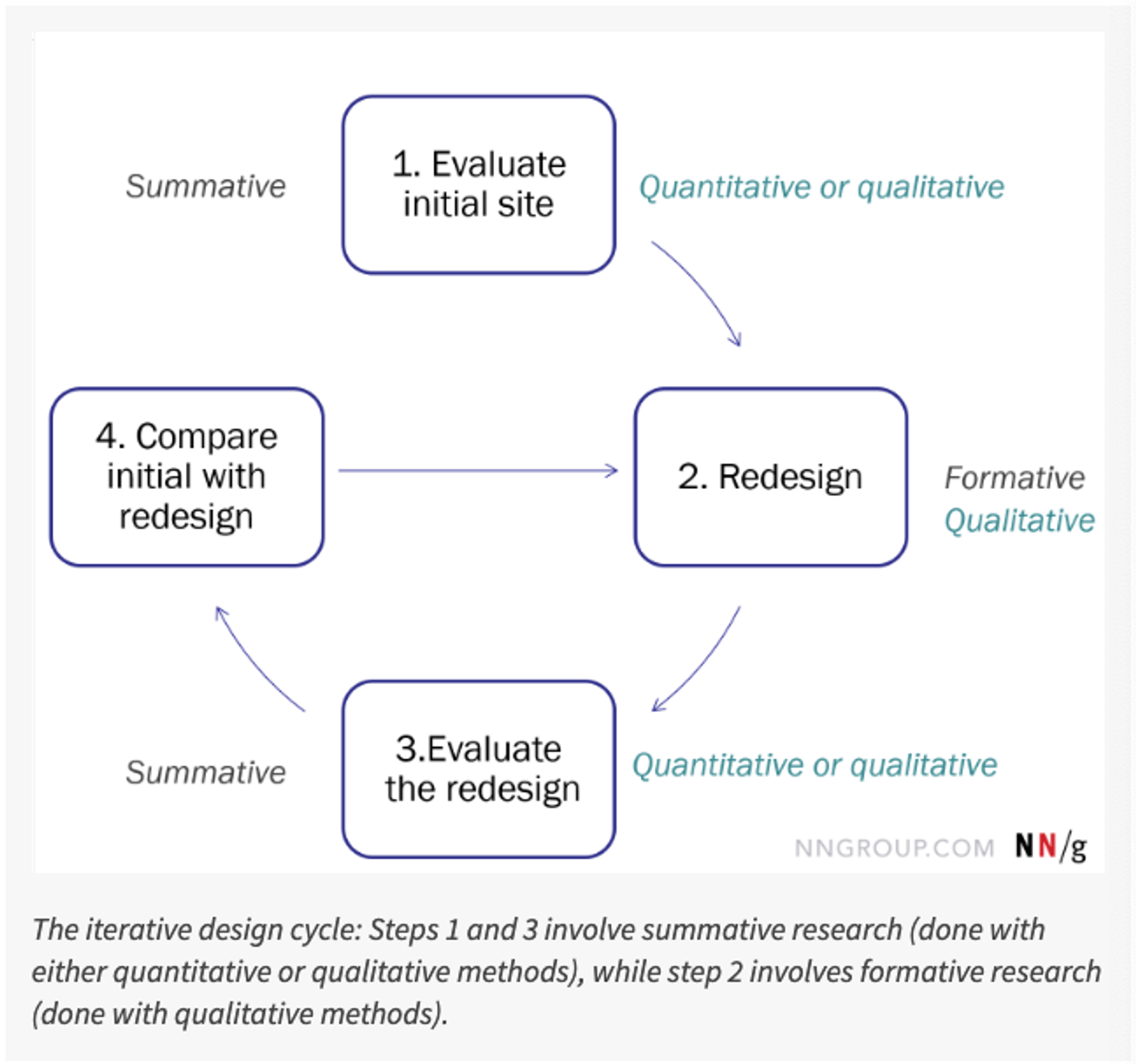
2.1.2. 언제 어떻게 수집할까?

언제 수집하느냐에 따라 나뉘는 분류
1.
태스크에 대한 평가 “Post-task ratings”, “Quick-ratings”
•
개념 : 개별 태스크가 끝나자마자 바로 수집
•
장점 : 특정하게 문제가 되는 태스크와 인터페이스의 부분을 바로 집어낼 수 있다.
•
목표 : 사용자들이 생각한 가장 어려운 태스크들에 대한 인사이트를 얻는 것이다.
2.
전체 경험에 대한 평가 “Post-study ratings”, “Overall experience ratings”
•
개념 : 전체 세션이 종료된 후 마지막에 수집
•
장점 : 효과적으로 전체에 대해 평가할 수 있다.
•
특이점 : 더 자주 보이는 형태로, Exit Survey와 같이 웹사이트에서 목적을 달성한 뒤에 수집하는 경우가 많다.
•
목적 : 하나의 연구 내에서 다양한 디자인 대안을 비교할 때 유용하다. 또는 당신의 제품 또는 웹사이트를 경쟁사와 비교할 때 유용하다.
사례 보기
Post-task ratings
Post-study ratings
어떻게 수집할 것인가
1.
언어적으로 말하기 : 개별 태스크가 끝나자마자 단일하고 빠르게 평가할 때 (Quick-ratings) 적절하다. 직접 실험자에게 말하기 때문에 불편한 말을 하지 못해 결과에 편향이 있을 가능성이 높다.
2.
종이에 작성하기: Quick-ratings, Post-study ratings에 모두 적절하다.
3.
온라인 툴으로 기입하기 : 랩탑을 두고, 온라인으로 직접 기입할 수 있게 한다. (e.g. Google Form, Qualtrics, Typeform, SurveyMonkey 등)
2.1.3. 설계 가이드라인 및 유의점
Social desirability bias
•
개념 : 익명 웹 서베이로 물어봤을 때보다, 사람과 만나거나 전화를 통해서 자기보고 데이터를 물어봤을 때 더 긍정적인 피드백을 주는 경향을 보인다.
•
이를 개선하기 위해, 서베이를 익명으로 만들거나 서베이를 작성할 때 평가자가 자리를 비우는 방법, 서베이를 집에 가서 작성하는 방법 등이 있다. 다만 몇 가지 방법은 서베이 완료 퍼널에서 이탈이 있다. 또한 집에 가서 작성하게 될 경우, 태스크를 수행하는 시간과 평가를 하는 시간 사이의 격차로 부정확한 결과를 보일 수 있다.
가이드라인
1.
다양한 척도를 활용할 경우 Triangulate될 수 있다.
참여자들에게 속성을 평가할 수 있는 다양한 방법을 설계할 경우, 더 믿을만한 결과를 얻을 수 있다. 다양한 척도로 평가 받은 뒤 평균 내어서 각 속성들을 비교할 수 있을 것이다.
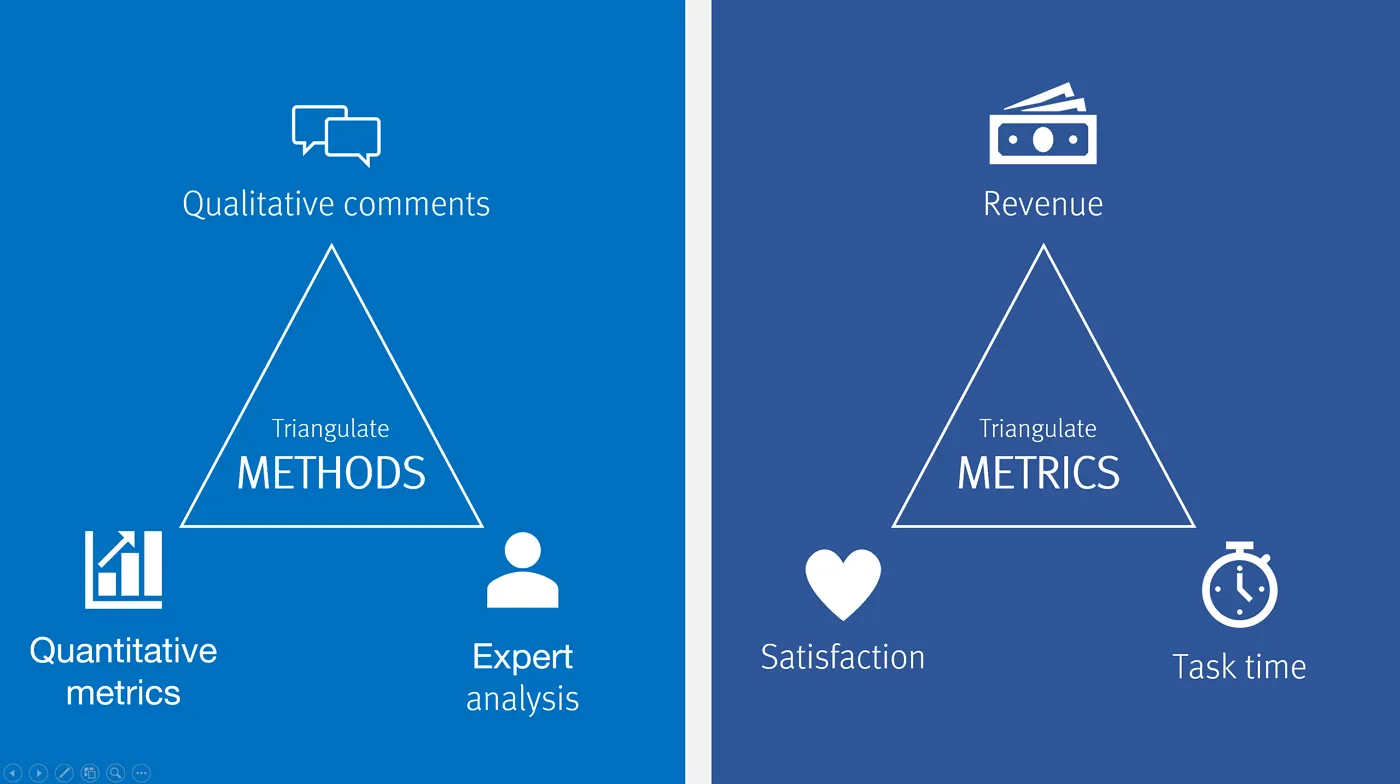
Some examples of research triangulation are:
•
Satisfaction metrics decline ⟶ you check revenue and time spent to see if they also changed
•
A quantitative usability test indicates low subscription-form success rates ⟶ you do a qualitative study to understand what features are problematic
•
Sales team reports that users think the software is hard to use ⟶ you do a usability study to observe problems.
•
Analytics data indicate a feature has high error rates ⟶ you check customer-support records to determine if problems are reported with this feature.
•
Interviews suggest a surprising purchase motivation ⟶ you do a survey to assess the frequency of that motivation.
•
One researcher notes several themes in interview transcripts ⟶ another researcher does a separate theme analysis to check if she finds the same themes
2.
포인트의 개수를 짝수로, 홀수로?!
뜨거운 감자인 주제이나, 본 책에서는 현실 세상에서는 중립적인 반응이 완벽하게 유효한 반응이며 평가 척도에 포함되어야 한다고 주장한다. 반대 연구로는, 중립 포인트를 포함하지 않는 것은, 대면으로 평가하게 되는 경우 ‘social desirability bias’를 약화할 수 있다.
3.
전체 포인트는 총 몇개 까지 가능할까?
9개가 넘는 포인트는 추가적인 유용한 정보를 주지 못한다.
4.
5-point scale이면 충분할까, 아니면 7-point scale이 나을까?
2가지 연구에서 7-point scale이 5-point scale보다 정확하거나 조금 더 낫다는 결과를 보였다.
5.
척도 개별 포인트에 숫자를 표기해야 할까?
본 책에서는 5개 ~ 7개를 넘지 않는 적은 포인트 개수라면, 각 자리에 숫자를 추가하는 것은 불필요하다고 보았다. 하지만 개수가 늘어난다면 참여자들이 잘 따라올 수 있도록 숫자를 추가하는 것은 유용하다. 대신, 0과 음수는 기입할 경우 참여자들이 안 누르려고 하는 경향이 있었다.
2.1.4. 분석 가이드라인
1.
예로 5-point 리커트 척도라면 숫자 1 ~ 5를 매겨서 평균 낸다. 엄밀히 인터벌 데이터는 아니지만, Degress of intervalness 가정에 따라서 각 척도 위치 간의 값이 유사하다고 보는 것이다. 이 때, 만족을 비율로 표현할 때도 있기 때문에 0으로 시작하는 것을 추천한다.
2.
응답의 실제 분포를 확인한다. 평균이 같은 2.5가 나와도 양 극단에 위치한 응답이 존재할 수 있다.
a.
2 / 2 / 3 / 3 (5점 만점, 4개 응답)
b.
1 / 1 / 3 / 5 (5점 만점, 4개 응답)
3.
양 극단에 위치한 아웃라이어를 육안으로 확인한다. 가장 싫어한 사용자들은 어떤 공통점을 가지는가? 가장 좋아한 사용자들은 어떤 공통점을 가지는가? 두 집단 간의 차이는 무엇인가?
4.
top-box 또는 top-2-box 점수로 분석한다. top-2-box는 주로 7,9 포인트 척도와 활용된다. 이 때는 인터벌 데이터가 아닌 빈도 데이터로 취급된다. top-box의 경우 이진 데이터로 표현되기 때문에 신뢰 구간을 Adjusted Wald Method를 통해서 계산할 수 있다.
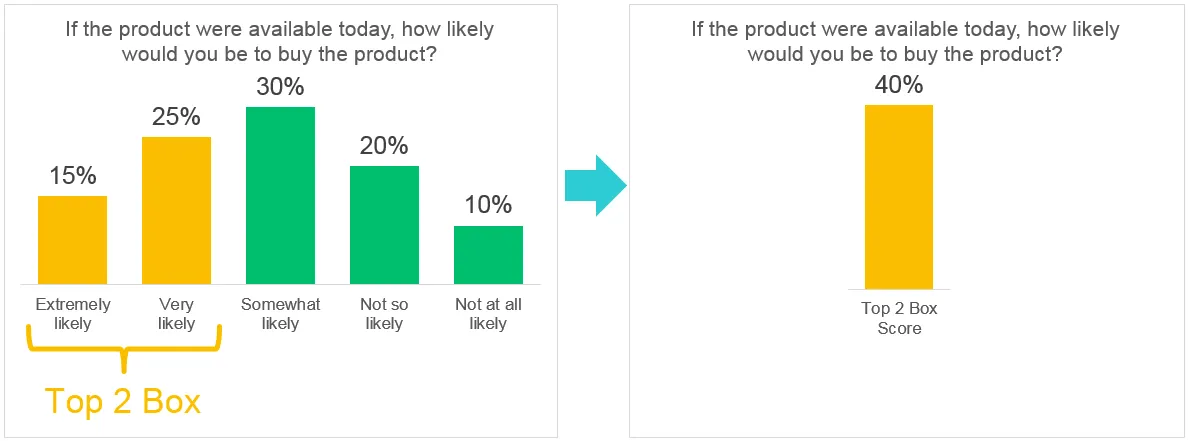
* 책에서는 단순 평균 내는 것을 추천하나, 종종 경영진들이 top-box-score에 익숙한 경우가 있다. 결과를 공유하는 대상을 파악하라.
2.2. 태스크에 대한 평가 (Post-task Ratings)
분류 다시보기
개별 태스크와 연관된 평가의 목표는, 사용자들이 생각한 가장 어려운 태스크들에 대한 인사이트를 얻는 것이다. 사용자에게 각 태스크를 하나 또는 그 이상의 척도로 평가해달라고 하는 방법이 있다.
본 책에서는 각 평가(Post-task ratings, overall user experience ratings, online services)에서 표준으로 많이 쓰이는 <평가 문항과 척도> 에 대해서 소개하고 어떤 <평가 문항과 척도>가 가장 비교적으로 뛰어난지 설명한다.
용이성 (Ease of use)
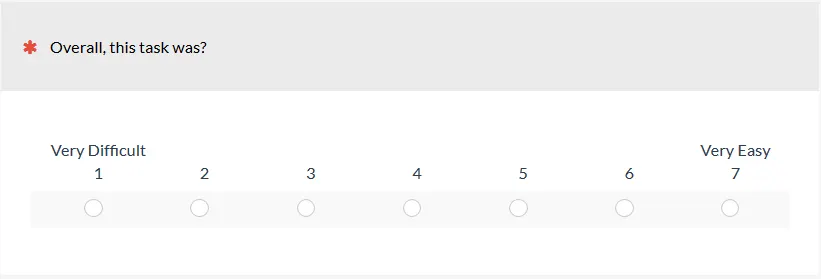
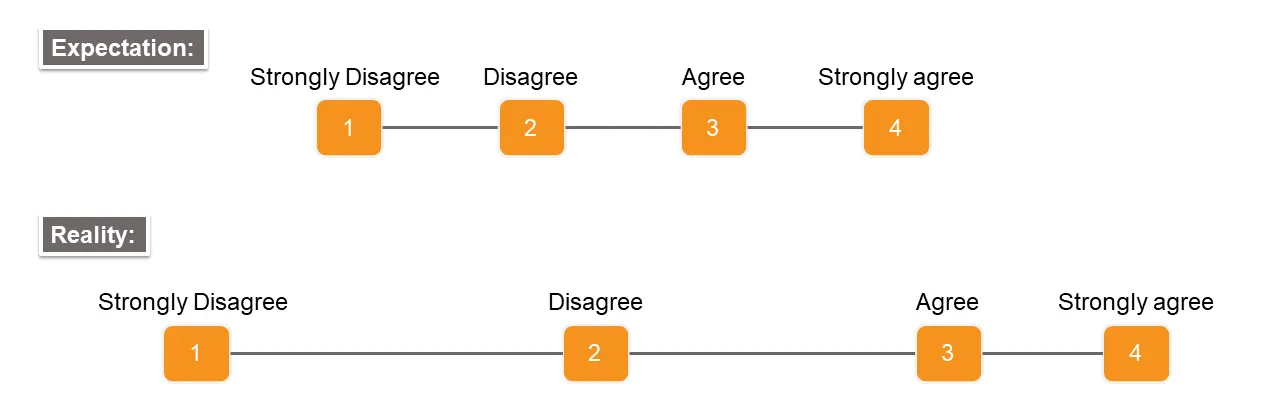
After-Scenario Questions (ASQ)

Expectation Measure
•
사용자가 생각했던 것에 비교했을 때, 얼마나 더 쉽거나 어려운가?
•
태스크를 수행하기 전에 설문을 받고, 수행한 후에 실제로 어땠는지 응답한다.
•
수행하기 전의 평가를 Expectation Rating, 수행한 후를 Experience Rating이라고 한다.
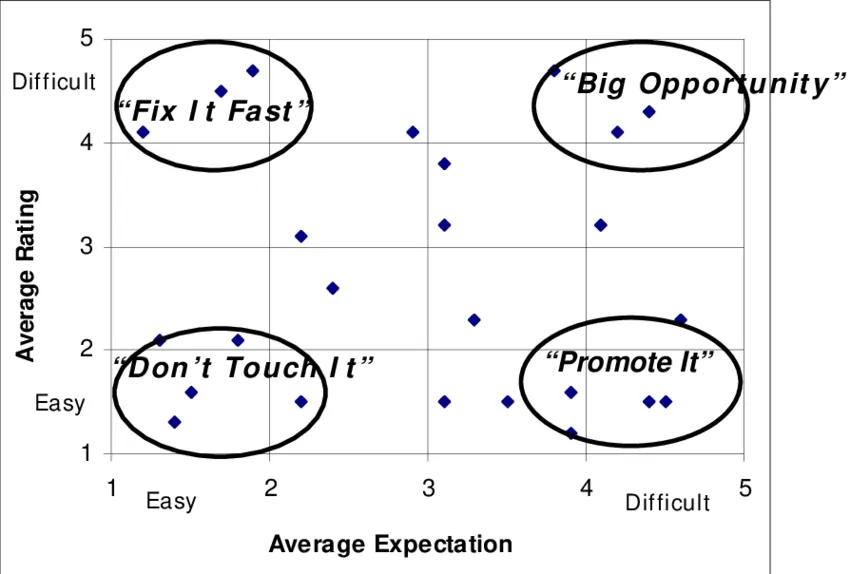
좌측과 같이, 2가지 축에 따라 4가지 분류로 구분해볼 수 있다.
1.
Fix it fast : 생각보다 어려워서 개선이 시급하다.
2.
Don’t touch it : 생각도 쉽고, 실제로도 쉬워서 최적화된 상태일 수 있어 변화했다가 부정적으로 변할 수 있다.
3.
Promote it : 생각보다 쉬워서 경쟁자들에 비해서 강점일 수 있다.
4.
Big opportunity :생각도 어렵고, 실제로도 어려워서 개선을 만들 수 있는 중요한 기회들이 많다.
어떤 평가 방식이 제일 좋은가요?
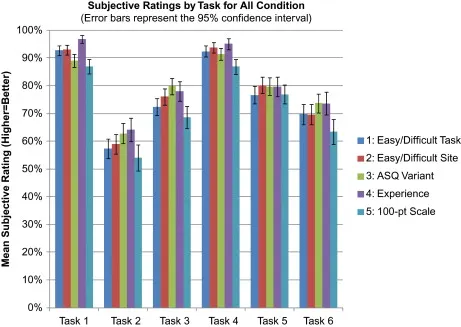
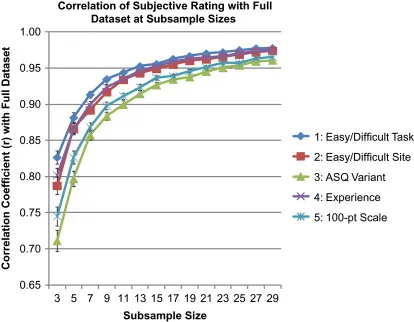
•
(우측) 용이성 (Ease of use) 이다. 적은 샘플 사이즈에서도 전체 데이터와 높은 상관계수를 보였다.
•
(우측) 전체 데이터에서 subsample을 뽑아서, 전체 데이터와 가지는 상관계수를 비교하면 sample size가 증가하면서 일정 수준에서 수렴하는 것을 확인할 수 있다.
2.3. 전체 경험에 대한 평가 (Overall User Experience Ratings)
분류 다시보기
전체 경험 평가의 경우, 하나의 연구 내에서 다양한 디자인 대안을 비교할 때 유용하다. 또는 당신의 제품 또는 웹사이트를 경쟁사와 비교할 때 유용하다.
본 책에서는 각 평가(Post-task ratings, overall user experience ratings, online services)에서 표준으로 많이 쓰이는 <평가 문항과 척도> 에 대해서 소개하고 어떤 <평가 문항과 척도>가 가장 비교적으로 뛰어난지 설명한다.
표준 <평가 문항과 척도> 를 사용했을 때의 장점
1.
편향되지 않은 데이터를 산출하기 위해 신중하게 제작되었으며 검증을 거쳤다.
2.
UX 문헌에서의 수 많은 연구가 표준 척도들을 활용했다.
3.
다양한 연구에서 벤치마크 데이터를 얻어 비교해볼 수 있다.
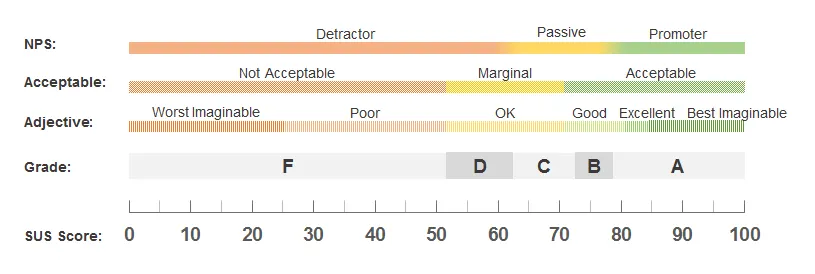
System Usability Scale (SUS)

•
시스템의 사용성을 평가하는 가장 널리 활용되는 방법
•
절반의 문장은 긍정적인 어조, 나머지 절반은 부정적인 어조이다. 어조가 섞여있기 때문에 참여자는 경각심을 가지고 응답에 임하게 된다.
•
계산하는 방법은 전체 숫자를 다 더한뒤 2.5를 곱한다.
•
해석 방법은 주요한 연구 2가지에 따라 다른데, Bangor et al.의 연구의 경우 아래에서 Acceptable과 Grade에 따라 분류하게 된다.
Net Promoter Score (NPS)
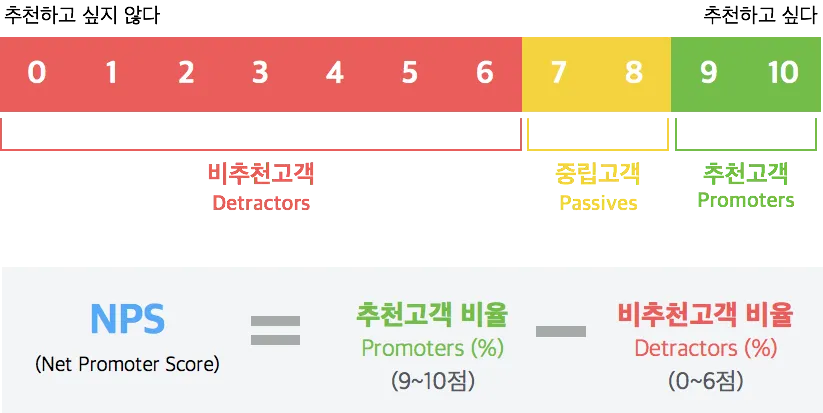
•
개념 : 사용자 로얄티에 대한 측정 지표
•
인기 있는 이유 : 단 하나의 질문에 의해 측정되므로 단순하면서 강력하다.
“How likely is it that you would recommend [this company, product, website] to a friend or colleague?”
(우리 서비스를 친구, 동료 등 주변인에게 추천하고 싶으신가요?)
사용성이 사용자 로얄티로 이어질까?
앞서서 SUS(사용성 측정)와 NPS(로얄티 측정)를 살펴보았는데, Jeff Sauro (2010) 연구에서는 SUS를 통해서 측정한 사용성이 NPS를 예측할 수 있는지 알고 싶었다.
상관관계 분석 결과, 0.61의 높은 상관계수를 보였으며 이는 p < 0.001으로 유의했다. 또한 추천 고객 세그먼트의 SUS 점수가 비추천 고객 세그먼트의 SUS 점수보다 1.2배 높았다.
기타 방법들
•
Computer System Usability Questionnaire
•
Product Reaction Cards (워드클라우드나 빈도 분석 가능)
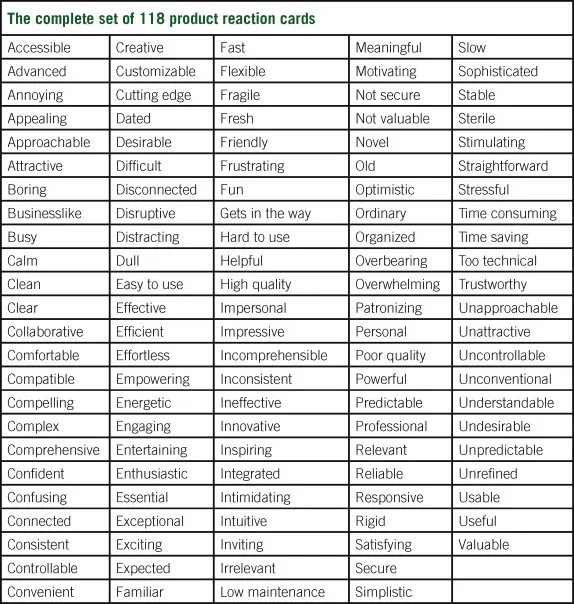
•
User Experience Questionnaire (UEQ)
•
AttrakDiff
•
Net
어떤 평가 방식이 제일 좋은가요?
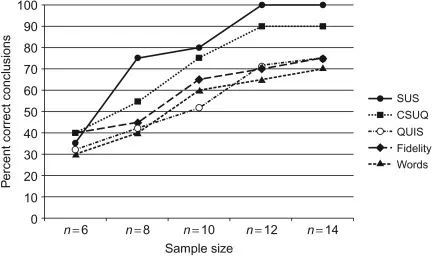
•
SUS이다. 샘플 사이즈가 적을 때에도 불구하고 일관된 평가 결과를 산출한다.
•
이것에 대한 이유로는, 긍정과 부정 어조가 섞여서 문항이 설계 되어서 평가자들이 더 경각심을 가질 수 있게 하는 것이 하나의 이유다.
2.4. Online Services
온라인 서비스에서의 자기보고 데이터 수집은, Voice of the Customers 즉 VoC Studies으로 불린다. 이는 자기보고 지표 중 전체 경험에 대한 평가와 유사하다.
2.4.1. 유의해야 할 것들
1.
질문의 개수가 많아질수록, 응답률이 저조해진다. 20개가 하나의 서베이에 포함될 수 있는 최대 질문 개수이다.
2.
응답자 선택 편향이 없어야 한다.
3.
응답자의 수가 충분해야 한다.
4.
응답자들이 서로 중복 소속되지 않아야 한다.
2.4.2. 방법들
스탠다드 메커니즘 및 기존에 활용되던 척도들을 활용하는 것을 권장한다.
•
Website Analysis and Measurement Inventory (WAMMI)
•
American Customer Satisfaction Index
•
OpinionLab
2.5. Other types of Self-reported Metrics
2.5.1. 우선순위 / 특정 속성 / 특정 요소 평가
우선순위 평가 지표
•
상황 : 신제품을 개발할 때, 제품 내의 기능 간의 상대적 우선순위를 결정하고자 할 때
•
방법 :
1.
기능을 모두 리스트 업한뒤, 사용자에게 중요도를 매겨달라고 한다.
2.
기능의 모든 쌍을 보여준 뒤, 어떤 쌍이 가장 평가자에게 중요한지 알려달라고 한다.
3.
Conjoint Analysis (1978년도에 개발된 통계 기법)
4.
기능 중에서 가장 좋은 것, 가장 나쁜 것 하나씩만 꼽게 한다.
5.
Kano Model (1984)
소비자들이 제품에 만족을 느끼는 요소를 크게 3가지로 분류할 수 있다.
Performance : 의도하는 대로 잘 작동하며 오랫동안 사용할 수 있는가?
Threshold : 예상한 대로 작동하는가?
Excitement : 예상치 못한 혁신적 기능이 있어 기쁨을 주는가?
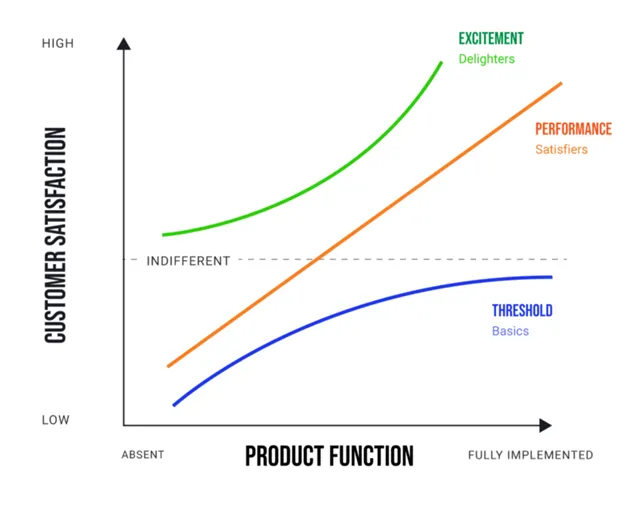
이 기능이 있다면 ~? 없다면 ~? 가정하여 제품에 대한 선호도를 5-point scale로 평가하게 한다.
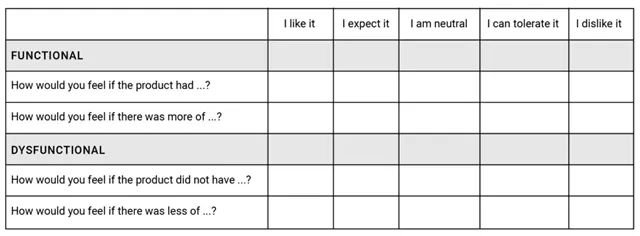
해석은 아래와 같이 할 수 있다고 한다.
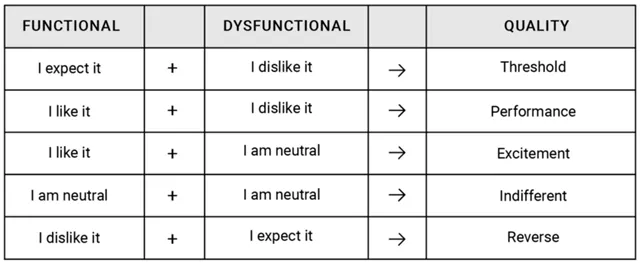
특정 속성 평가 지표
•
상황 : 제품의 특정 속성/ 성질들에 대해 집중한 연구를 하고 싶을 때
•
책에서는 아래 속성/ 성질들에 대해 대표적인 연구 및 툴을 소개한다.
◦
Visual appeal, Trust, Visual appeal & Ease of use, Crediblity
특정 요소 평가 지표
•
상황 : 제품의 특정 요소에 대해 평가하고 싶을 때 (e.g. FAQ, 안내 페이지, 사이트맵, 홈 페이지 등)
•
책에서는 2가지 대표 툴을 소개한다.
1.
Nielsen Norman Group (2002)
2.
Tullis (1998)
2.5.2. 주관식 질문 (Open-ended questions)
수집 방법 2가지
1.
개별 평가 척도 이후 바로 코멘트를 추가할 수 있게 한다. 계산이 어려워도 개선점을 찾는 데에 유용하다.
2.
제품에 대해 가장 좋아한 3-5가지와, 가장 안 좋아한 3-5가지를 작성하게 한다. 단어의 빈도를 계산하는 방식으로 지표로 치환 가능하다.
분석 가이드라인
1.
Word Cloud : 날 것 그대로의 응답을 복사한 뒤 워드 클라우드 툴으로 워드 클라우드를 만든다.

2.
Filtering : 크게 두드러지는 단어에 대해서, 해당 단어를 포함한 모든 날 것 그대로의 응답만 모아서 본다.
(예시) ”Services”를 포함하는 모든 코멘트를 찾아라!
3.
Manual Analysis : 카테고라이징, 태깅을 통해 하나하나 코멘트를 보며 카테고리를 붙여준다. 카테고리들을 기반으로 향후 정량적인 분석이 가능하다.
(예시) ”Services are generally useless” : 기능성 태그
2.5.3. 인식과 이해 (Awareness & Comprehension)
Performance data VS Self-reported data
•
두 가지를 가르는 명확한 차이를 희미하게 만드는 기법이 있다. 바로, 사용자들이 태스크를 수행한 뒤에 웹사이트를 다시 방문할 수 없게 막은 상황에서 어떤 것들을 보았고 어떤 것들을 기억하는지 물어보는 방법이다.
•
웹 사이트의 다양한 기능에 대한 인식에 대한 체크가 가능하다.
•
어떤 콘텐츠가 사용자에게 두드러졌는가?에 관심이 있다.
측정하는 방법 2가지
1.
웹 사이트를 보여준다. → 웹사이트를 더 이상 못 보는 상태에서 “웹사이트에 있었던 콘텐츠를 선택하시오”라는 질문지를 받는다.
2.
웹 사이트를 보여준다. → 웹사이트를 더 이상 못 보는 상태에서 “웹사이트에 실린 특정 정보에 대해 이해했는가?”를 알 수 있는 퀴즈를 푼다.
이 때, 사용자가 사전 지식이 없는지 사전에 테스트하여 사후 테스트 결과와 비교하는 것이 좋다.
우발학습 (Incidental Learning)
•
태스크를 수행하며 웹사이트와 상호작용하는 동안, 특정 정보로 공공연히 안내되지 않아도 이루어지는 학습
•
주의를 다른 곳에 쏟고 있어 어떤 것을 학습하려는 의도가 없는데도 이루어지는 학습
인식과 유용성 격차 (Awareness-Usefulness Gap)
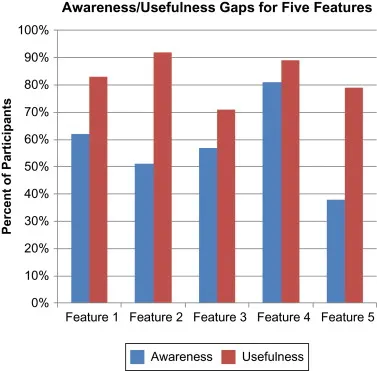
•
“잘 인지한다고, 유용한 것은 아니다.”
◦
사용자가 기능을 인지하는 순간, 굉장히 유용하다고 느끼며 더 홍보하거나 강조하라고 이야기할 수도 있다.
•
이 격차를 해결하기 위해 두 가지 문항을 모두 연이어 바로 물어보는 것이 좋다.
1.
이 연구 전에 기능에 대해서 미리 알고 있었나요? (Yes, No)
2.
이 기능이 평가자에게 얼마나 유용한가요? (1-5)
이 때, 척도 결과를 Top-2 Box Score(Binary)로 치환시켜 비율 기준으로 비교하는 것이 좋다. 좌측과 같이!
2.6. Summary
1.
태스크 레벨, 전체 레벨으로 모두 자기보고 데이터를 수집해라. 태스크 레벨 데이터의 경우, 개선이 필요한 영역을 정의할 수 있게 해주는 장점이 있다. 전체 레벨 데이터는 완성된 사용자 경험에 대한 감을 얻을 수 있게 돕는다.
2.
시스템에 대한 주관적인 반응은 <표준 설문지>를 활용하는 것을 고려해라. 특히 SUS가 적은 사용자 수로도 강건한 결과를 보여 추천한다.
3.
제품을 다른 경쟁자와 비교하고 싶거나 벤치마킹하고 싶을 때, 가능한 출판된 연구에 있는 SUS, UEQ, SUPR-Q, WAMMI, ASCI 의 <표준 툴>을 활용할 수 있다.
4.
제품 내에서의 기능들에 대한 사용자들의 우선순위를 알고 싶다면, Conjoint Analysis, MaxDiff, Kano model을 활용할 수 있다.
5.
가능하다면 하나의 주제에 대해서 다양한 방식으로 평가 척도를 설계하여 결과를 받은 후, 그 결과에 대해 평균 내어 더 일관된 결과를 얻어라. 물론 새로운 평가 척도를 설계할 때 신중하라.
6.
사용자가 제품과 상호 작용한 뒤 인식과 이해한 정도를 확인하기 위해 주관식 질문을 추가하라.

원문
Mesuring the user experience CH. 04 - 05
Discussions
PAP에서는 스터디 구성원들이 세션 진행 후 주제 발제를 통해 논의를 진행합니다.
이번 세션 내용 중에 새롭게 알게되었거나 인상 깊었던 점, 실제 활용해보면 좋을 것 같은 방법 등 각자 의견을 자유롭게 공유해주세요
현재 개선하고 있는 피쳐는 무엇인가요? 또한 해당 피쳐를 평가한다면, 언제 평가하시겠어요?( “Post-task ratings”/ “Quick-ratings”) 그리고 어떻게 데이터를 수집하여 평가하시나요? 간단한 경험을 공유해주세요.
정기적으로 모니터링하는 Self reported data(앱 평점, 자체 만족도 조사 등)가 있나요? 결과값을 어느 정도의 중요도로 받아들이나요?
(QnA) 이용 경험에 대한 사용자 만족도를 팝업으로 수집하고 싶은데, 하고 계신 분 있나요?
Editor

최보경 데이터 분석가
옆 동네 데이터 분석가, 데이터로 유저의 행동을 이해하고 인과관계를 파악합니다. 제품을 접하는 사용자에 대해서 더 알고 싶은 마음에 데이터에서 출발하여 정량 UX 스터디를 시작하게 되었습니다.



.png&blockId=187f136b-17e0-41c1-a1c5-d0659000409c)
